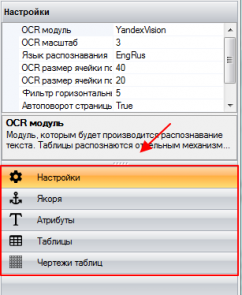
Панель настроек В правой панели основного меню Шаблонизатора находятся 5 основных блоков для создания и настройки шаблона: 1.Настройки 2.Якоря 3.Атрибуты 4.Таблицы 5.Чертежи таблиц